고감도 질량분석기를 이용하여 단백질 정량분석을 수행하면 대략 수천개의 단백질이 검출됩니다. 이러한 수천개의 단백질 중에 많은 수의 단백질이 증감을 보입니다. 하지만 질량분석기기의 데이타 특성상 False-positive 결과를 완전히 제거하는것은 불가능합니다. 얻어진 스펙트럼과 데이타베이스에서의 스펙트럼과의 매칭을 통한 검출과정에서 많은 요소들이 포함됩니다. 하지만 이 단계에서 어떤 단백질을 선택해서 다음 단계로 넘어가야 하는지 결정하는것은 쉬운 일은 아닙니다.
사실 너무 많은 수의 단백질이 차이를 나타내기 때문에 오히려 더 분석이 어렵다고 합니다. 어떤 때는 차이나는 단백질중 보기에 좋은(?) 단백질을 취사선택하는 경우도 종종 있습니다. 일일이 다 확인 할 수 없기때문이다. 하지만 잘못된 결정은 차후 Antibody등을 이용하는 실험에서 많은 시간과 돈이 낭비될수 있습니다. 이러한 이유로 분석후 이차 통계분석은 다음 단계로 넘어가기전에 거쳐야 아주 중요한 단계입니다.

다행히도 요즘 상용화 된 프로그램들은 이러한 작업을 자동으로 수행되기 때문에 질량분석기에만 익숙한 나같은 사람에게는 큰 도움이 됩니다. 그래도 데이타에서 보여주는 여러 통계학적인 용어나 개념을 어느정도 알고 있어야 되지 않을까 생각해 봅니다.
자신이 직접 분석한 두 그룹에서 측정된 특정 단백질의 양의 차이가 유의적인지 측정할때 기본적으로 쓰는 방법이 T-test입니다. 즉 T-Test는 두 그룹간의 평균이 유의적인 차이를 갖는지를 확인할때 쓰이는 통계분석 법입니다.
T-Test를 위한 통계적 추론(statistical inference)
T-test를 하는 근본적인 이유는 시료군에서 측정한 값이 실제 모집단의 특성을 잘 대변하고 있는지 확인하는 것입니다. 우리가 취한 시료가 모든 경우를 잘 대변할 수 있어야 합니다. 예를 들면 100명의 간암환자의 시료를 분석하여 얻은 결과가 이 세상의 모든 간암환자에서 얻은 결과를 잘 대변할수 있어야 합니다. 이러한 통계적 추론을 기반으로 T-TEST가 이루어집니다. 예를 들면 얻어진 결과중에 양적으로 변화를 많이 가지는 단백질 확인한후 이 단백질과 그 값이 흥미가 있을지를 확인합니다. 만약 그렇다면 차이나는 값이 실제로 진짜 인지를 확인하기 위해서 통계분석을 수행합니다. 통계분석을 수행후 얻어진 값을 근거로 결과의 유의미성을 판단하게 됩니다. 또한 T-Test 분석으로 얻어지는 최종값은 보통 p-value로 나타냅니다. 즉 이 p-value가 의미하는것이 아는것이 무엇보다도 중요합니다.

다시말하자면 Signal 이 noise보다 크면 통계적으로 유의하고 반대의 경우는 유의적인 않다고 말할 수 있습니다.

종종 두 그룹간의 비교결과를 바(bar) 그래프로 나타냅니다. 하지만 바 그래프 (왼쪽)의 경우 각 그룹에서 측정된 값의 분산도(Variablity) 를 확인 할 수 가 없습니다. 이 분산도는 T-TEST에서 아주 중요한 요소이기 때문에 이 분산도를 반드시 고려해야 됩니다.

Variability의 중요성
통계분석을 하는 이유중 하나는 실험에서 얻어진 두 시료간의 차이가 진짜인지 확인하는것입니다.
예를 들면 개의 실험군에서 차이를 발견하였습니다. 뭔가 의미가 있게 느껴집니다. 하지만 이것이 진짜인지 가짜인지 확인이 필요합니다. 이때 필요한것이 통계분석입니다. 그 결과를 보여주는것이 t, F값들입니다. 차이가는것이 충분히 큰 차이인지를 알려줍니다. 하지만 이때 각각의 시료군에서의 variability가 중요합니다. 한개의 시료군에서도 차이가 많이 나게 되면 문제가 됩니다. 아래의 그림과 같이 두 실험(위 와 아래)에서 얻어진 차이값은 동일합니다. 하지만 각각의 실험에서 얻어진 값들의 분포도가 확연히 다릅니다. 즉 동일한 차이값을 보이더라도 아래 그림에서 보여지듯이 high variability를 가지는 실험에서 얻어진 값은 유의적이지 않게 됩니다.

즉 T-TEST는 각각의 그룹에서 얻어진 측정치값들의 분포를 고려하여 실제 값 (Signal)이 유의한지를 나타냅니다. 그룹간의 평균값과 각 그룹의 변수를 모두 고려한 것입니다. 이러한 분포도 그래프는 측정된 시료수에 따라 크게 변할수 있습니다. 보통 30개 이상의 시료의 경우 정규분포도 모양을 나타내지만, 시료의 수가 적으면 양쪽 꼬리가 보다 더 크게 퍼지게 됩니다. 그러므로 적은 시료의 수로 분석한 결과는 불확실성이 더 커지게 됩니다. 최대한 많은 시료의 수를 확보하는것이 중요한 이유입니다.

그러므로 이러한 실험에서 얻어진 결과를 보여주기 위해서는 아래와 같은 그래프가 적절합니다. 이 3가지 그래프는 Normality (정규분포) 와 Homogeneity of variance (분산의 이질성)을 적절히 표현해 낼수 있습니다. 바 그래프는 이러한 차이점을 보여주지 못합니다.

GraphPad Prism 프로그램을 예로 t-test를 수행하는 방법은 아래와 같습니다. 아래 그림에서 보듯이 데이타를 기입한후 메뉴에서 Analysis- Analyze Data-Column Analyses-t-test를 클릭합니다.
Experimental Design에서 unpaired 와 paired 중에 선택한다. unpaired 의 경우 두 그룹에서 사용한 시료(환자,동물 등)가 서로 다른 경우이며 (예, 동일한 약물을 서로 사람에 주입) paired 는 동일한 시료(환자)에 적용된 경우이다(예, 동일한 환자에 한 약물은 서로 다른 시간에 따라 주입).

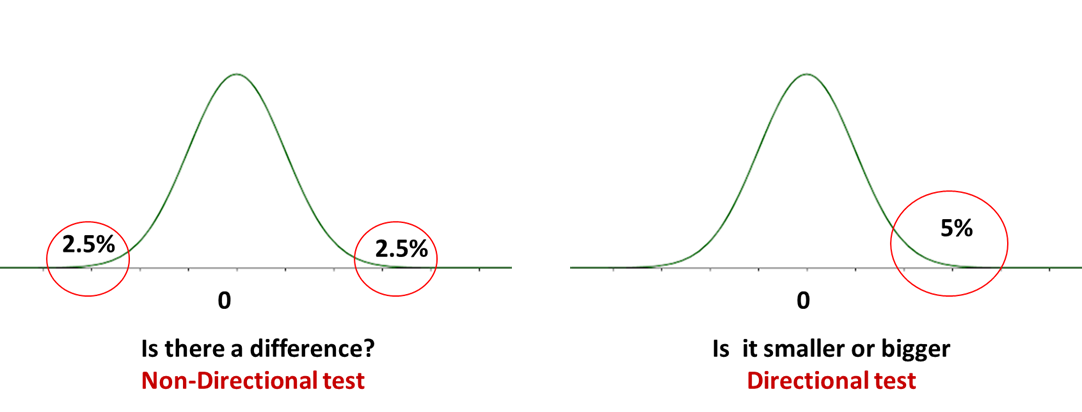
또 하나 중요한 요소가 p 값의 계산시 one-tailed 와 two-tailed 를 선택하는 것입니다.

(아주 아주 간단히 이해한 바로는) 두 그룹간의 차이를 비교 할때 양수, 혹은 음수가 나올 수 있는 경우에는 two-tailed 을 사용합니다. 예를 들면 두 환자 그룹간의 특정 단백질의 상대적인 변화를 관측할때 증가되거나 감소 될 수 있는 경우 입니다. One-tailed 의 경우 한쪽 방향으로의 측정일 경우에 사용합니다. One-tailed 와 two-tailed의 선택 여부는 실험의 디자인에 따라 결정되어야 합니다.
'프로테오믹스(단백체학)' 카테고리의 다른 글
| PNGase-F 효소로 N-linked glycopeptide 위치 찾기 (0) | 2020.06.28 |
|---|---|
| N-linked glycopeptides 가 C18 Chromatography에서 상호작용하는 원리 (0) | 2020.06.28 |
| (초보통계학) Normality (정규성)와 분산의 동질성(Homogeneity of variance) 확인 하는 법 (0) | 2020.06.22 |
| p 값에 대해 간단한 해석 (0) | 2020.06.22 |
| Formic acid(F.A) 와 trifluoroacetic acid (TFA)의 Trap-column에 대한 펩타이드 결합력 비교 (0) | 2020.06.21 |



댓글